今天学习了Python简单爬虫,爬了一个表情包网站: [http://www.doutula.com/] ,以后聊天斗图不怕没表情包了,下面是完成的代码,分享给大家
import requests
from lxml import html
from concurrent import futures
import time
import os
etree = html.etree
headers = {
'Referer': 'http://www.doutula.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)' +
' Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0'
}
def download_img(img_url, dir_name, img_name):
img_format = img_url.replace('!dta', '').split('.')[-1]
filename = img_name + "." + img_format
print(img_url, img_name, filename)
# filename = src_url.split('/')[-1].replace('!dta', '')
dir_name_s = 'imgs/{}'.format(dir_name)
if not os.path.exists('imgs'):
os.makedirs('imgs')
if not os.path.exists(dir_name_s):
os.makedirs(dir_name_s)
if not os.path.exists('imgs/all'):
os.makedirs('imgs/all')
img = requests.get(img_url, headers=headers)
with open('imgs/{}/{}'.format(dir_name, filename), 'wb') as file:
file.write(img.content)
with open('imgs/all/{}'.format(filename), 'wb') as file:
file.write(img.content)
print(img_url, filename)
def get_page(url):
time.sleep(0.001)
resp = requests.get(url, headers=headers)
dir_name = url.split('page=')[-1]
print(resp, url)
html_str = etree.HTML(resp.text)
img_s = html_str.xpath('.//img/@data-original')
img_name_s = html_str.xpath('.//div[@class="col-xs-6 col-sm-3"]/img/@alt')
exe = futures.ThreadPoolExecutor(max_workers=40)
print(len(img_s), len(img_name_s))
for i in range(len(img_s)):
exe.submit(download_img, img_s[i], dir_name, img_name_s[i])
next_link = html_str.xpath('.//a[@rel="next"]/@href')
return next_link
def main(start_page_num=1, end_page_num=4):
next_link_base = 'http://www.doutula.com/article/list/?page='
next_link = 'http://www.doutula.com/'
current_num = start_page_num - 1
while next_link:
time.sleep(0.2)
current_num += 1
next_link = get_page(next_link_base + str(current_num))
if current_num >= end_page_num:
break
if __name__ == "__main__":
main(start_page_num=101, end_page_num=109)
'''页面链接格式
http://www.doutula.com/article/list/?page=1
http://www.doutula.com/article/list/?page=2
http://www.doutula.com/article/list/?page=3
http://www.doutula.com/article/list/?page=4
'''
'''图片链接格式
http://img.doutula.com/production/uploads/image//2018/11/03/20181103474657_oXHzJM.gif!dta 20181103474657_oXHzJM.gif
http://img.doutula.com/production/uploads/image//2018/11/03/20181103474657_tkfgCQ.gif!dta 20181103474657_tkfgCQ.gif
http://img.doutula.com/production/uploads/image//2018/11/03/20181103474658_ueRcby.gif!dta 20181103474658_ueRcby.gif
https://ws4.sinaimg.cn/bmiddle/6af89bc8gw1f8o03g63ypj207f0ammx3.jpg 6af89bc8gw1f8o03g63ypj207f0ammx3.jpg
https://ws2.sinaimg.cn/bmiddle/6af89bc8gw1f8oyzh4zy9j204e04emx1.jpg 6af89bc8gw1f8oyzh4zy9j204e04emx1.jpg
https://ws3.sinaimg.cn/bmiddle/6af89bc8gw1f8p6zsv91oj2068068q31.jpg 6af89bc8gw1f8p6zsv91oj2068068q31.jpg
https://ws1.sinaimg.cn/bmiddle/6af89bc8gw1f8ppr3fnaag203c037js7.gif 6af89bc8gw1f8ppr3fnaag203c037js7.gif
'''
'''图片HTML格式
<img src="//static.doutula.com/img/loader_170_160.png"
style="margin: 0 auto; min-height: inherit;"
data-original="https://ws4.sinaimg.cn/bmiddle/6af89bc8gw1f8rlirv225j20a00a0750.jpg"
alt="没有表情包,我怎么装逼"
class="img-responsive lazy image_dta"
data-backup="http://img.doutula.com/production/uploads/image//2016/05/27/20160527315611_jIzUAx.jpg!dta">
'''运行效果:

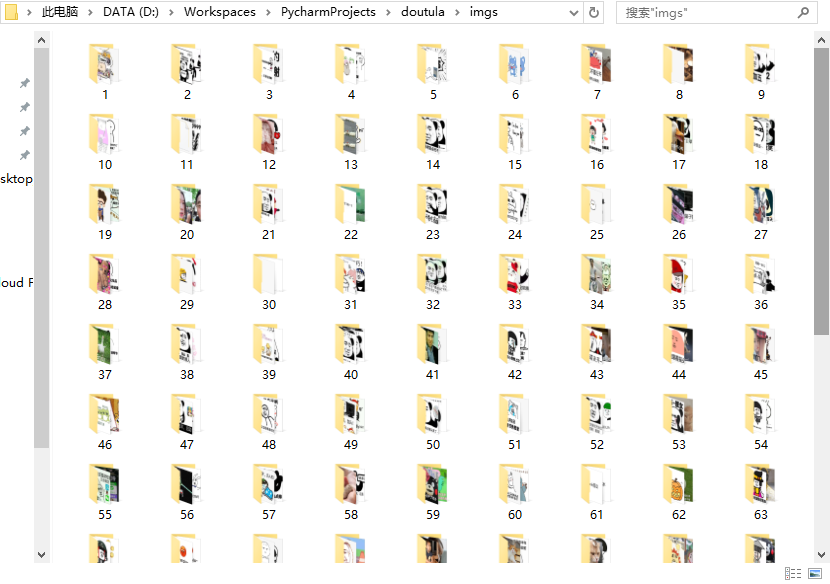
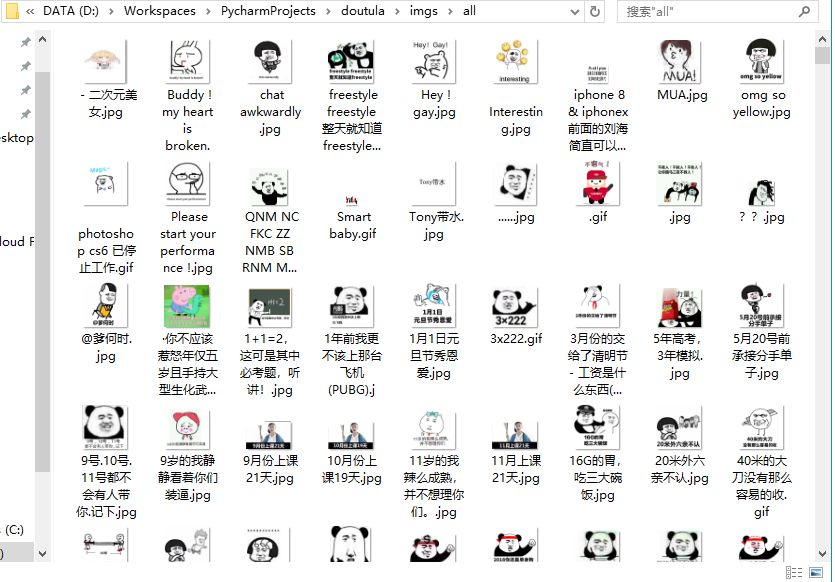
- 本文固定链接: https://www.coordsoft.com/post/10.html
- 转载请注明: admin 于 生活随想 - zwgu 's world 发表
楼上的很有激情啊!https://www.2kdy.com